LLMETA : A.I. based metadata extraction
2024.03 ~ 2024.06
Project Details
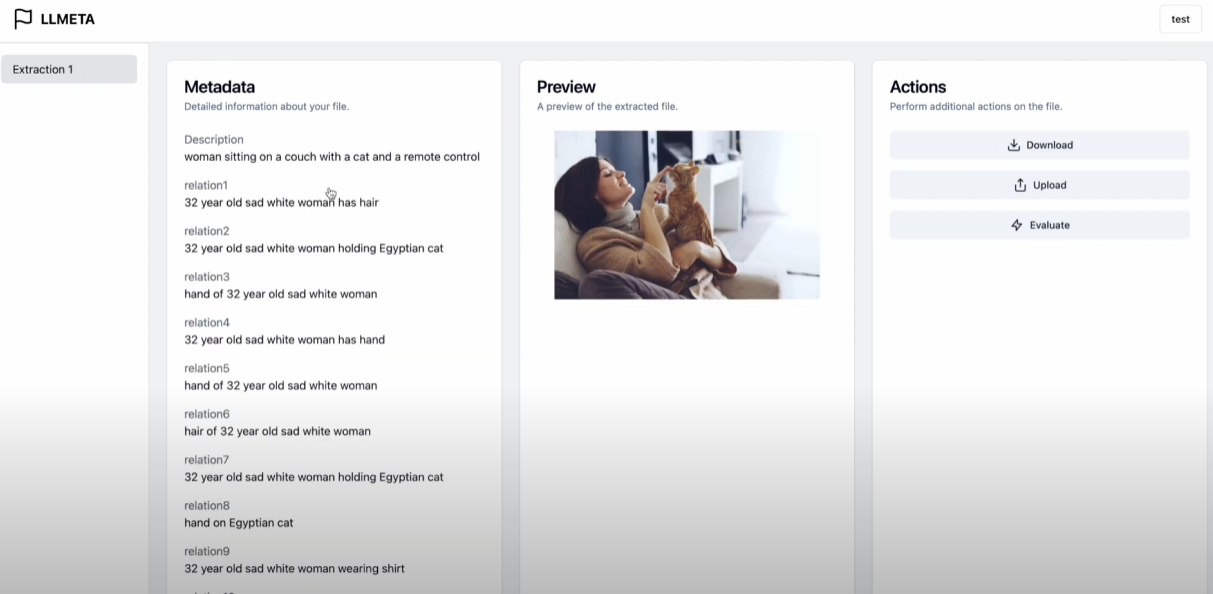
The significance of metadata in information retrieval and data management is rapidly increasing, To enhance usability of metadata extraction of research papers and images, we propose an advanced method that surpasses existing techniques 2x accuracy by leveraging Large Language Model (LLM) and deeper classifiable Scene Graph Generation (SGG).
Goals
1. Extract paper metadata by applying prompt engineering and RAG to llama2-7b
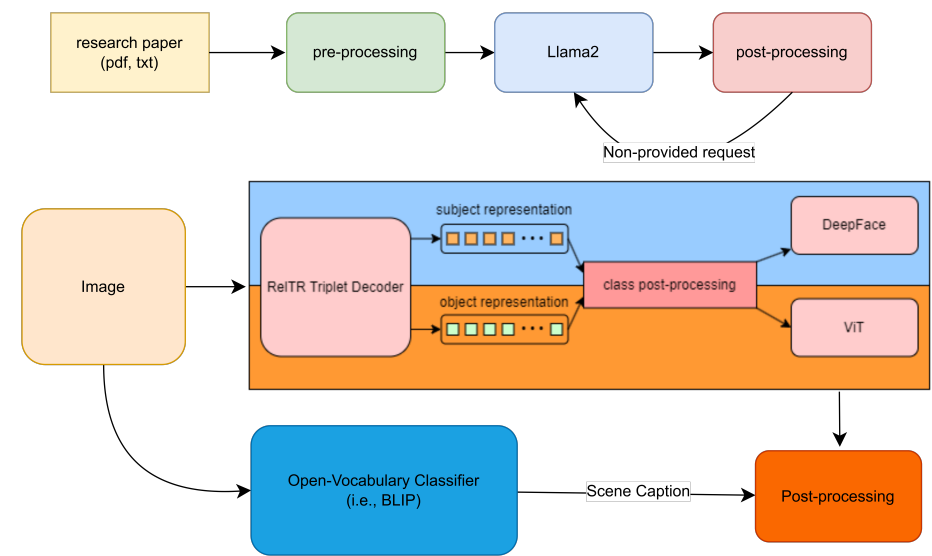
2. Generate image metadata by Relation Transformer integrated with DeepFace, ViT
3. Develop vision models to classify more classes even breeds
Technologies
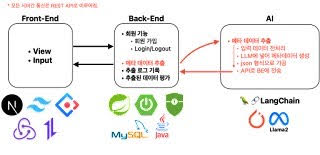
FrontEnd - Next.js, tailwindCSS, Figma
BackEnd - Spring, SpringBoot3, SpringSecurity, MySQL, RDS, NginX, AWS EC2
A.I. - PyTorch, Langchain, transformers, Flask
Team
[A.I.] ByungHyun Kim, [BE] DaYoung Kim, HyeWon Seok, [FE] SeokHee Kim
[Github Organization] [Paper]